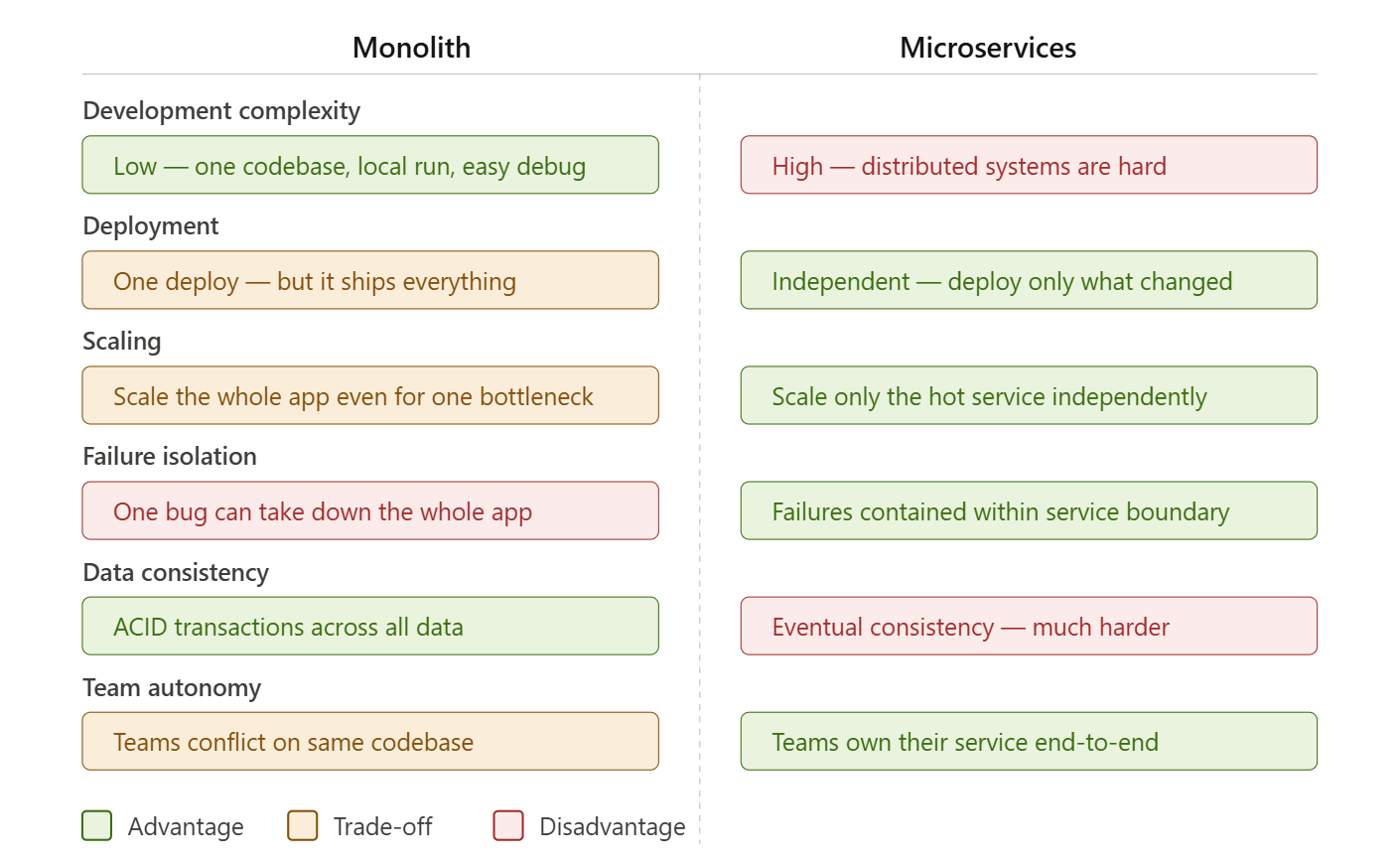
Monolithic Architecture (Monolith)
A monolith is a single, unified application where all modules (auth, product, payments, notifications..) are packaged and deployed together.
HLD Structure
┌──────────────────────────────────────────┐
│ Monolithic App │
│ ┌────────────┬─────────────┬───────────┐ │
│ │ Auth │ Orders │ Payments │ │
│ ├────────────┼─────────────┼───────────┤ │
│ │ Inventory │Notifications│ Analytics │ │
│ └────────────┴─────────────┴───────────┘ │
└──────────────────────────────────────────┘
▲
│ Single DB
▼
┌─────────┐
│Database │
└─────────┘
Characteristics
- All modules share one codebase and are deployed at once
- Inter-module communication happens via in-process function calls – extremely fast
- One database (typically) serving the whole app
- A single CI/CD pipeline ships the entire thing
- Simple to develop locally – clone, run, done
Where monoliths shine: Early-stage startups, internal tools, small teams, and any system where the domain is not yet well understood.
Pros:
- Simple HLD and Development
Single codebase, easier onboarding - Simple Deployment
One build -> one deployment - Shared Memory & DB
No network calls; faster function calls. - Easy Local Dev
Everything runs in one place
Cons:
- Single Point of failure
- Scaling Limitation
Must scale entire application, even if only one module needs capacity. - Tight Coupling
A change in one module affects the whole system. - Slower deployments with size
As the app grows, deployment becomes heavy. - Reduced Fault Isolation
One bug can crush everything. - Hard to implement polyglot tech stack
Must use same language/framework.
When to Use Monolith
- Early-stage startup / MVP.
- Small engineering team.
- When domain is not yet clearly defined.
- When performance is more important than modularity.
- When features are highly interdependent.
Microservices Architecture
A microservices architecture splits the system into independent, loosely-coupled services, each owning a specific business capability. They communicate over a network – via REST APIs, gRPC, or message queues.
Monolith Modules -> ServicesHLD Structure
┌───────────────┐
│ API Gateway │
└───────┬───────┘
│ Route
─────────────────────────┼──────────────────────────────
▼
┌──────────┐ ┌───────────┐ ┌───────────────┐
│ Auth Svc │ │ Order Svc │ │ Payment Svc │
└─────┬────┘ └─────┬─────┘ └──────┬────────┘
│ │ │
┌─────▼───┐ ┌─────▼───┐ ┌─────▼──────┐
│ Auth DB │ │ Order DB│ │ Payment DB │
└─────────┘ └─────────┘ └────────────┘
Other HLD components:
- Service Discovery (Eureka/Consul)
- API Gateway (Kong, Nginx, Zuul)
- Load Balancers
- Message Broker (Kafka, RabbitMQ)
- Centralized Logging (ELK, Loki)
- Tracing (Jaeger, Zipkin)
Characteristics
- Each service has a single business responsibility
- Services communicate over the network (HTTP, gRPC, AMQP)
- Each service own its own data store – no shared database
- Services can be deployed, scaled, and even rewritten independently
- Technology diversity is possible – one service in GO, another in Python
Pros:
- Independent deployability
Deploy only the service you modify. - Independent scaling
Scale only high-load services (ex: search or checkout) - Fault Isolation
Failure in one service does not kill the entire system. - Polyglot flexibility
Different services can use different languages/DB. - Clear Domain Separation
Each service is complete bounded context.
Cons:
- Complex HLD
Requires DevOps maturity (gateway, CI/CD, logs, tracing). - Distributed System Challenges
Network issues, retries, timeouts, async communication. - Eventual Consistency
Synchronous consistency becomes harder - Operational Overhead
Many repositories, many deployments. - Cross-cutting Concerns
Need centralized logging, monitoring, metrics.
When to Use Microservices
- Application is large and rapidly growing.
- Teams are big and work on independent modules
- Need independent deployments.
- Different modules need different scaling modules.
- Need high availability
- Domain boundaries are clear
The hardest Problem in microservices
Microservices promise scalability, flexibility, and independent deployments. But they also introduce a set of challenges that are far more complex than what you face in a monolithic system.
1 Distributed Transactions
In a monolith, managing transactions is straightforward:
- You wrap multiple operations in a single database transaction
- Either everything succeeds, or everythign rolls back (ACID guarantees)
Example:
- Create order
- Deduct inventory
- Both succeed or both fail
Problem in Microservices
In a microservices architecture:
- Order Service has its own database
- Inventory Service has itw own database
You can't perform a single ACID transaction across both.
Solution: Saga Pattern
Instead of one global transaction:
- Break it into multiple local transactions
- Each step has a compensating action (rollback)
Flow:
- Create order
- Deduct inventory
- If step 2 fails -> cancel order
Why it's Hard:
- No automatic rollback
- You must manually handle failures
- System can enter inconsistent states temporarily
- Requires careful orchestration or choreography
2 Network Latency & Partial Failures
In an monolith:
- Function calls happen in-process (nanoseconds)
- Failures are predictable and easier to handle
Problem in Microservices:
In distributed systems:
- Calls happen over the network (milliseconds)
- Networks can:
- Fail
- Timeout
- Be slow
Worst case:
Service A calls Service B, times out…. but B may have already processed the request.
Why It's Hard:
- You don't know the true state of the system
- Retrying blindly can cause duplicate actions
- Failures are partial, not absolute
Required Solutions
- Circuit Breakers -> stop repeated failures
- Retries with Idemopotency -> safe re-execution
- Timeouts -> avoid hanging requests
- Fallbacks -> graceful degradation
3 Observability
In a monolith:
- One codebase
- One log stream
- One stack trace
Debugging is relatively straightforward
Problem in Microservices:
A single requirest might:
- Travel across 5-10 services
- Generate logs in multiple systems
When something breaks:
Where did it fail?
Why It's Hard
- Logs are distributed
- Failures are indirect
- No single place to trace execution
Required Solutions:
- Distributed tracing (track request across services)
- Centralized logging (aggregate logs)
- Metrics & monitoring dashboards
- Correlation IDs to tie everything together
Different Phases of a Microservice
When people say “phases of microservices”, they usually mean the lifecycle of adopting and maturing a microservices architecture – not just building services, but evolving the whole system.
Microservices are not just “small services” – they requires a full lifecycle of phases to design, build, operate, and evolve.
Below are the essential phases:
1 Decomposition Phase
This is the first and most critical phase.
monolith -> microserviceThis tells us if you have a monolith application, then how will you break it down to the microservice architecture.

The decomposition phase decides how the system is split into services:
There are two design patterns for decomposition:
- Decomposition by business logic
- Decomposition by sub domain
1 Decomposition by business logic
Each service is designed around a business capability – a function the business performs. Identify the entities of the business then breakdown according to them.
Say: Zomato handles orders, payments, users, restaurants.
Then we break these business logic into microservice.
OrderService
PaymentService
UserService
RestaurantService
All are deployed on different servers, all communicate through http calls.Examples:
- Payment Service
- Order Service
- Inventory Service
- User Service

Disadvantages:
- Developer should be aware of entire business. However it is better for the entire team.
2 Decomposition by Subdomain
Split system based on bounded contexts in Domain Driven Design. We break sub domains.

3 Decompose by Strangler Pattern (Incremental Migration)
It is not the other type but an implementation of the above two types of decomposition.
It answers “How will you do it?”
“Don't replace the sytem – replace it piece by piece.”
When migrating monolith -> microservices, we change it step by step.
Steps:
Start with the existing monolith
All traffic goes to the old system.
Client -> MonolithIntroduce a routing layer (proxy/gateway)
This sits in front of your system and decides:
- what goes to the monolith
- what goes to new services
Client -> Gateway -> MonolithBuild a new service for one feature
Pick a small, low-risk component
- e.g., Notifications, Search, Auth
Redirect traffic gradually
Client -> Gateway -> New Service (for some routes) -> Monolith (rest)- Expand service by service
- Keep Extracting:
- Orders
- Payments
- Users
- Keep Extracting:
Decommission the monolith
Eventually:
Client -> Gateway -> Microservices only
2 Database Phase
Once we have decomposed the system into services, the next step is to decide how each service handles its data.
This phase focuses on:
- Data ownership
- Database per service
- Schema design
- Consistency model
- Data communication between services
- Transaction patterns
- Query patterns
Each microservice can have:
Shared DB (avoid):
All microservices share one database. This gives us free cross-table JOINs, easy ACID transactions. The problem surfaces when we try to scale or evolve independently.

Advantages:
- Simple to carry operations
- Join (SQL)
- Transaction manage (ACID)
Disadvantages:
- Can not be scaled independently.
- Has the limitation of either being SQL or NoSQL. Individual service has no choice of DB model selection.
Unique DB (ideal):
Every service has their own database. They can't call each other's DB directly. They have to call the respective service to get data. For instance; order service can't call the payment's DB directly. However it can get data by calling the payment service.

Advantages:
- Flexibility for every service to choose the DB model according to their need.
- Service database can be scaled independently.
Disadvantages:
- JOIN
- If we two services named restaurants and orders, and we have to find how many orders placed in a restaurant, then we got to use the JOINS but we can't because their DB is separate and might be deployed on different servers and their model could also be different one could be
SQLother could beNoSQL. - We have Design Pattern
CQRSfor this problem.
- If we two services named restaurants and orders, and we have to find how many orders placed in a restaurant, then we got to use the JOINS but we can't because their DB is separate and might be deployed on different servers and their model could also be different one could be
- Transaction Management (How to know commit, rollback across different services)
- Normal Flow: User create an order, change is done in order DB then it payment's DB and at last at the Restaurant's DB.
- Abnormal Flow: If order is created and payment is cancelled, then how does the User's service get to know about this and do rollback.
- SAGA Pattern solves this problem.
3 Communication
How two microservices communicate with each other, whether through APIs or event driven system.
4 Deployment
How your microservices will be deployed. It is handled by the DevOps through CI/CD.
5 Observability
How will we monitor the application. It is also handled by the DevOps through CI/CD.
Canary Deployment
Canary deployment is a release strategy where you roll out a new version of your application to a small subset of users first, instead of everyonw at once.
If everything works fine, you gradually release it to all users.
If something breaks, you roll it back.
How It Works
- Deploy new version (v2) to a small group (e.g., 5% users)
- Remaining users still use the old version (v1)
- Monitor:
- Errors
- Latency
- User behavior
- If stable -> increase traffic (20% -> 50% -> 100%)
- If issues -> rollback to v1
Why the Name “Canary”?
Comes from the historical use of canary birds in coal mines:
- If toxic gas appeared, the canary would be affected first
- Warning humans early
Similarly, a small user group “tests” the release.
Key Components
- Load Balancer: Routes a % of traffic to new version
- Monitoring System: Detects failures
- Features Flags: Enable/disable features dynamically
SAGA Pattern (Solves Transaction Management)
Saga Pattern is a distributed transaction management pattern used in microservices to maintain eventual consistency across multiple services without using distributed locks or 2-phase commit.
A Saga is a sequence of local transactions across multiple services.
Each step:
- Updates its own database
- Publishes an event (or triggers next step)
If something fails:
- Execute compensating transactions (undo steps)
In a monolith:
BEGIN TRANSACTION
update orders
update payments
update inventory
COMMITWorks because:
- Single DB
- ACID guarantees
In microservices:
- Each service has its own database.
- No global transaction
So this breaks:
Order DB ≠ Payment DB ≠ Inventory DBYou cannot do a single ACID transaction across them.
Example: Order System
Services:
- Order Service
- Payment Service
- Restaurant Service
Successful Flow:
1. Order Created, Change in its DB and call the next service
2. Payment Deducted, Change in its DB and call the next service
3. Restaurant Receives Order, Change in its DB
4. Order ConfirmedFailure Case:
If payment fails:
1. Order Created ✅
2. Payment Failed ❌, It will rollback its own state, but what about the order service.
How order service will get this information.SAGA solves this problem using Event Driven System.
Why Saga Is Needed
In microservices:
- Each service has its own DB
- Distributed transactions are slow and risky
- Network failures are common
Saga solves this by splitting a transaction into steps, with compensating actions to undo a step if later steps fail.
Definition:
A Saga is a sequence of local transactions where each local transaction:
- updates data within its own service
- publishes an event or sends a command to trigger the next step
If a step fails:
- A compensating transaction is executed to undo the previous steps.
Beak a transaction into a sequence of local transactions + compensating actions
Instead of:
All succeed or all fail (ACID)You do:
Step-by-step execution + rollback via compensationTwo Types of SAGA
Saga has two major architecture patterns:
1 Choreography Saga (Event-Driven)
Microservices communicate via events. No central controller. Services react to events.
Flow:
Order Service → Inventory Service → Payment Service → Shipping Service
Each Service:
- listens for an event
- performs its local transaction
- emits the next event
Example Flow (E-commerce):
- Order Service
- Local transaction: create order
- Emit event:
OrderCreated
- Inventory Service
- On
OrderCreated: reserve stock - Emit:
InventoryReserved
- On
- Payment Service
- On
InventoryReserved: ship item - Emit:
OrderShipped
- On
Failure Example:
If payment fails:
- Emit
PaymentFailed - Inventory Service listens -> rollback reservation
- Order Service listens -> cancel order
Pros:
- Simple
- Decentralized
Cons:
- Hard to track flow
- Debugging is difficult
2 Orchestration Saga (Centralized Coordinator)
A Saga Orchestrator or “workflow engine” controls the flow.
A central orchestrator controls the flow.
Flow:
Saga Orchestrator → Auth Service
→ Payment Service
→ Inventory Service
→ Shipping Service
Example (E-commerce):
- Orchestrator sends:
CreateOrder - Order Service returns:
OrderCreated - Orchestrator sends:
ReserveInventory - Inventory ->
InventoryReserved - Orchestrator ->
ProcessPayment - Payment ->
PaymentCompleted - Orchestrator ->
ShipOrder
If payment fails:
- Orchestrator sends:
ReleaseInventory - Orchestrator sends:
CancelOrder
CQRS (Command Query Responsibility Segregation) (Solves the JOIN problem)
CQRS is an architectural pattern that separates write operations (commands) from read operations (queries) instead of using the same data model for both.
Command = Write operations (update, delete, insert)
Query = Read operations (select)
The Core Problem in Microservices
In a monolith:
SELECT *
FROM orders o
JOIN users u ON o.user_id = u.id;Works because:
- Single database
- Joins are easy
In microservices:
- User Service -> has its own DB
- Order Service -> has its own DB
You cannot join across databases/services directly.
How CQRS Helps?
1 When data is written (Command side)
Example:
- User places an order
Order Service saves:
{
"order_id": 1,
"user_id": 42
}2 Event is published
Order Service emits event:
OrderCreated(user_id=42, order_id=1)3 Read model is built (Query side)
A separate Read Database is created like:
{
"order_id": 1,
"user_name": "Rahul",
"order_total": 500
}This DB is denormalized
It already has everything – No JOIN needed
Analogy
Think of it like:
- Microservices = separate shops
- You need a combo meal (burger + drink)
Without CQRS:
- You go to 2 shops every time
With CQRS:
- Someone already packed a combo for you 🍔🥤
Trade-offs
Pros:
- Fast reads (no joins)
- Scales well
- Works with microservices
Cons:
- Data duplication
- Eventual consistency (data might be slightly delayed)
- More complexity
Circuit Breaker
Scenario
- Service A depends on Service B
- Service B becomes slow or goes down
Now A keeps doing:
A → B ❌
A → B ❌
A → B ❌Every request still tries to call B
Why This Is Dangerous
1 Slow Response (Timeout Storm)
Each request:
- Waits for timeout
- Blocks threads/resources
System becomes slow
2 Resource Exhaustion
- Threads pile up
- Connection pools fill
- CPU/memory usage spikes
Service A can crash – even though it's healthy
3 Cascading Failures
- Service A slows down
- Now Service C (which depends on A) also slows
Failure spreads across system
4 No Fast Failure
Without circuit breaker:
Request → wait → timeout → failEvery failure is slow and expensive
The real problem is not just failure – it's continuing to hit a failing service repeatedly
How Circuit Breaker Fixes It
Step 1: Detect Failure Pattern
- Too many errors / timeouts
- Failure threshold crossed
Step 2: “Open the Circuit”
Stop calling the failing service:
A → ❌ (blocked immediately)No network call
No waiting
Step 3: Fail Fast
Instead of waiting for timeout
- Return error instantly
- Or use fallback
Step 4: Recovery (Half-Open)
After some time:
- Allow a few test requests
If successful:
- Resume normal flow
Before vs After
Without Circuit Breaker
A → B (slow/failing)
→ timeout
→ retry
→ timeout
→ system overload 💥With Circuit Breaker
A → B (fails repeatedly)
→ circuit opens
→ A stops calling B
→ fast failure ⚡
→ system stable
Leave a comment
Your email address will not be published. Required fields are marked *