The Dark Side of Caching: Problems You Can't Ignore
There is famous saying in computer science:
There are only two hard problems in computer science:
- Naming things
- Cache invalidation
At first, caching feels like magic.
You add a cache; your system becomes fast, database load drops, everything looks perfect.
But then reality kicks in.
Caching doesn't remove complexity – it shifts it.
Because once we implemented cache, a lot of problems start to show up. Let's walk through the most important ones.
1 Cache Stampede (Thundering Herd)
It happens when a popular cache entry expires via TTL. Suddenly a flood of requests all try to rebuild that cache at the same time and so even if that windows lasts just a second, every single one of those cache misses is going to hit our database, turning one query into thousands or even millions, ultimately overwhelming the database.
Imagine you have some website for which cache the homepage feed with a TTL of 60 seconds. You don't want it to cache it too long because you don't want it to get too stale. 60 seconds is what you choose and then we get millions of requests every second. All millions requests because all users need that home feed, they hit us the cache and everything works great. but after 60 seconds it expired, and what happens when it expires in the case of cache aside is going to ask for it from the database and update the cache. But in that millions of requests come into the cache, they all fail, and then they all go try to hit the database, and it could take the database down, overwhelm it, and cause cascading failures. Now there's two common ways to prevent this.
First request coalescing or single flight. Both fancy names, but the idea is actually really simple. When a request tries to rebuild the same cache key or when multiple requests try to rebuild the same cache key, the only the first one should work and the rest of them should wait for the result to come and then read from the cache. That's the first most common way to handle it.
The second is called cache warming. The way it works is that instead of waiting for popular keys to expire, waiting full 60 seconds, you can proactively refresh them just before they die. Say at the 55 second mark, we could come to the database and refresh the feed. Thus giving us another 60 seconds. We just keep refreshing every 55 seconds so that it remains fresh and no stale.
Problem
When a hot key expires, thousands of requests miss the cache at the same time and all hit the DB.
Impact:
- DB overload
- Massive Latency spikes
- Full system outage
- Cascading failures
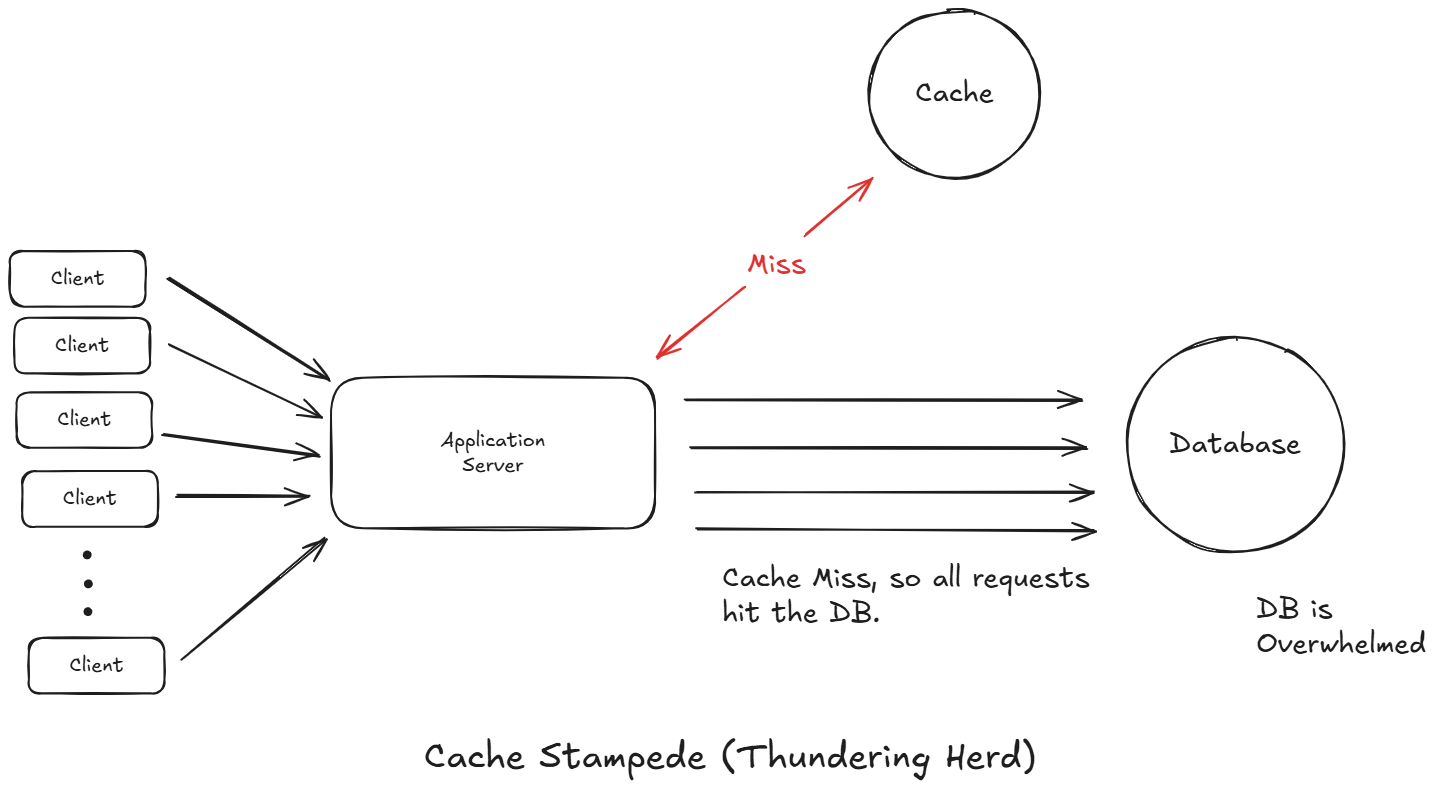
Solutions:
1 Request Coalescing (Single Flight)
Only one request rebuilds the cache, others wait.
First request -> fetch from DB
Others -> wait -> read cached resultPrevents duplicate work..
2 Cache Warming (Proactive Refresh)
Instead of waiting for expiry:
TTL = 60s
Refresh at 55sCache is never empty.
3 Stale-While-Revalidate (Advanced)
Serve stale data temporarily:
User → gets old data (fast)
Background → refreshes cacheUsers don't feel latency spikes.
2 Cache Inconsistency
Imagine you have a social network and user updated their profile picture. and that new value is written to the database, but that old one is still sitting out there in the cache, now other users who are requesting hitting the cache and they are getting image 1. They are getting the old one. Despite the fact we had already updated the database to image 2. They are going to continue to read the value until this ends up being evicted for some reason.
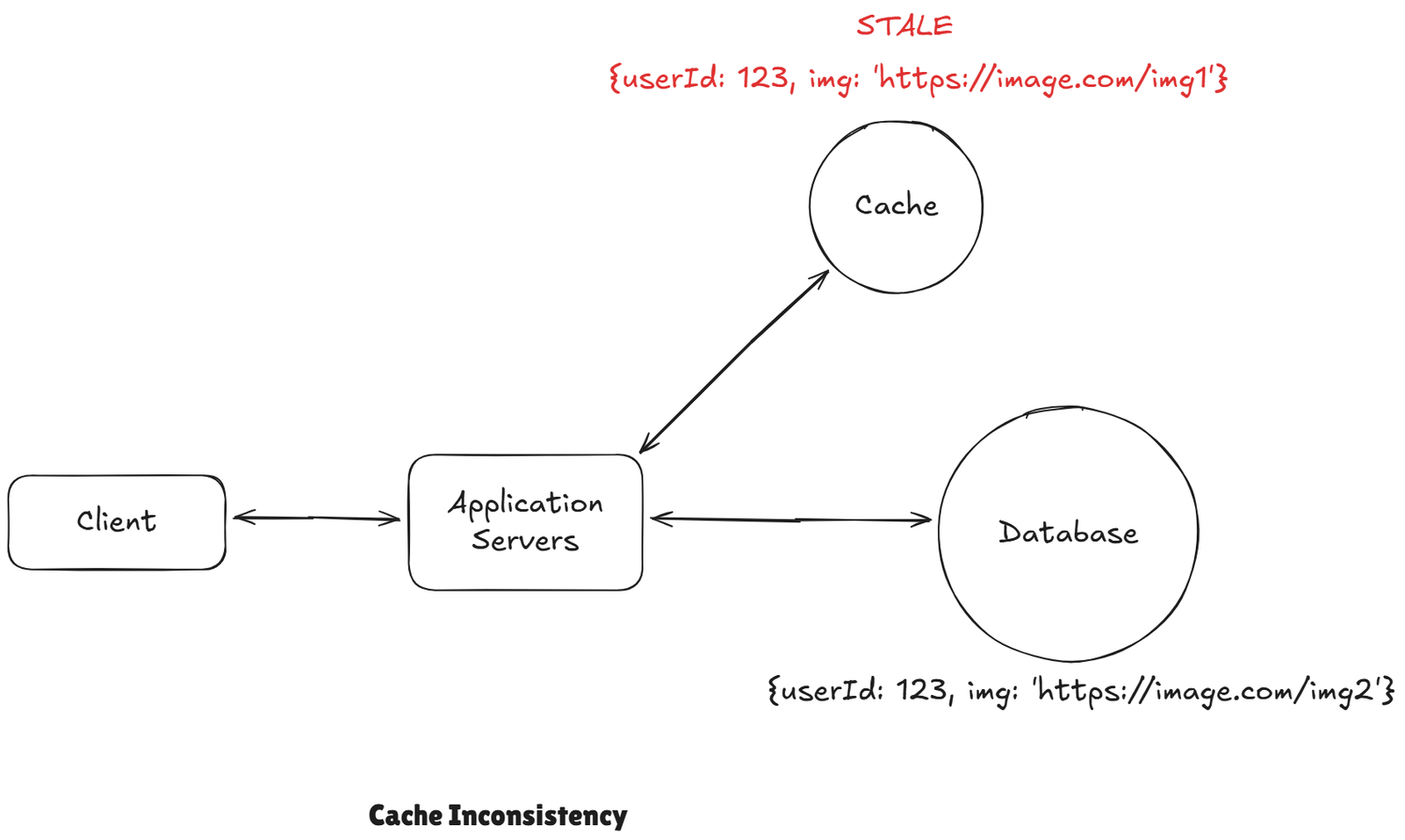
There is no perfect fix for this. It very much depends on how fresh your data needs to be. That is case-by case basis. There are some common strategies.
First is to invalidate on write. If consistency is important when that profile is updated in database then we could also go delete that key proactively from the cache. This way next time read comes in we would see that it's missing and we would go grab it from the database and update the cache. This would be process of invalidating on write.
You can also just short TTLs, so if some stay on this is acceptable, you can keep the cache entry but have a TTL short.
Problem:
DB is updated but cache still returns old data.
Impact:
- Wrong data shown to users
- Financial or trust loss
Fixes:
- Write-through
- Explicit invalidation
- Pub/Sub eviction
- Versioned cache key
- Short TTL for critical data
Solutions:
1 Invalidate on Write (Most Common)
- Update DB
- Delete cache
Next read will fresh data loaded.
2 Write-Through
Write -> Cache -> DB
- Keeps both in sync
- Slower writes
3 Pub/Sub Invalidation
Using tools like Redis:
- One service updates data
- Publishes event
- All services invalidate cache
4 Versioned Cache Keys
user:123:v1 → old
user:123:v2 → newAvoids stale reads completely.
5 Short TTL
Accept slight staleness:
- Data refreshes quickly
- Simpler system
3 Hot Keys
Hotkeys is a cache entry that gets way more traffic than anything else. Even if your overall cache hit rate is great, everything is working as planned, that single key can still become a large bottleneck for the system. For example, you building Instagram and everyone is viewing dhanda nyoliwala's profile, that cache key for the profile could be receiving millions of request per second. One key can overload a single Redis node or shard even though that shard or cache is technically working as expected.
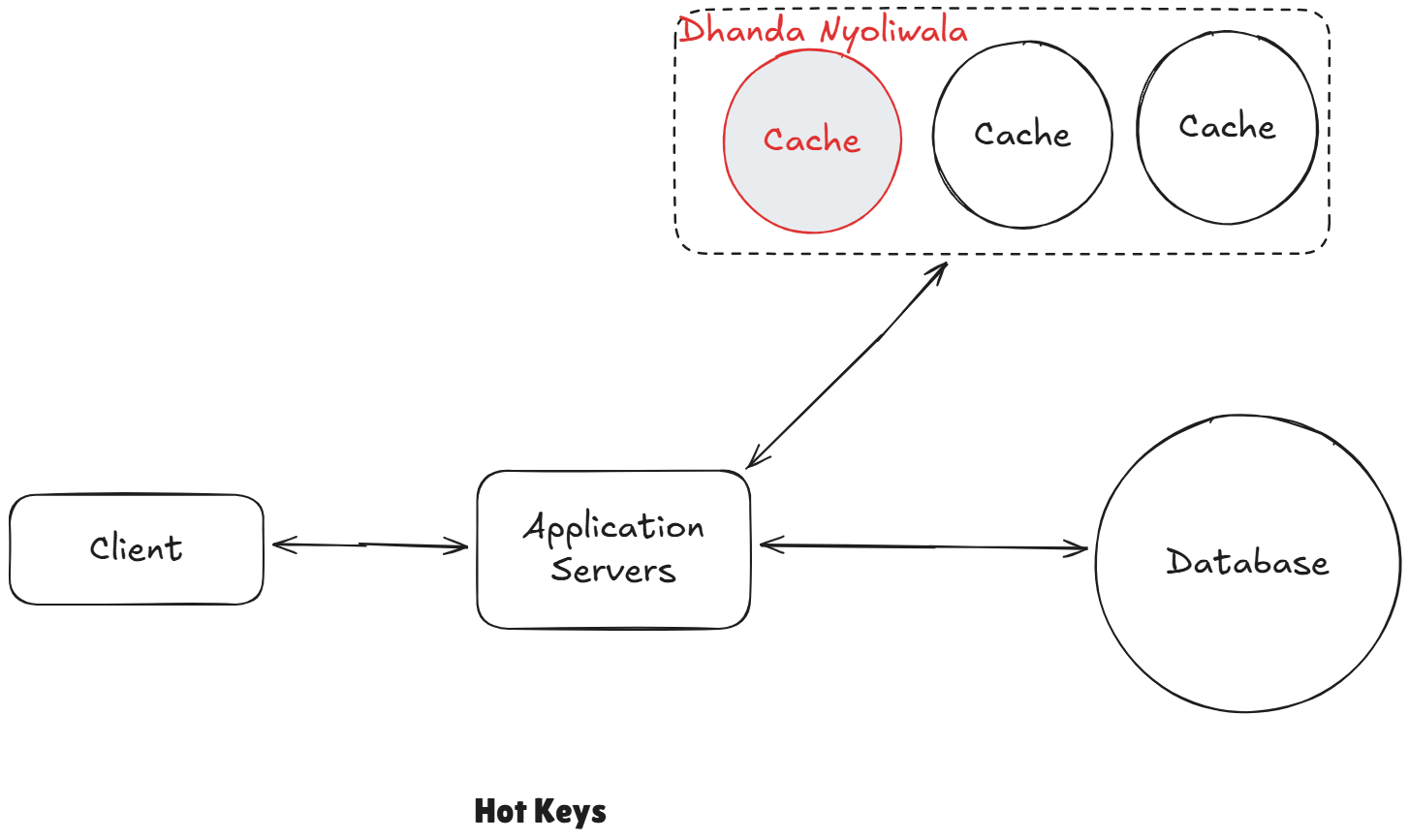
The first solution is to replicate this hot keys, you can put dhanda nyoliwala on each of different cache cluster.
Another solution is to add a local fallback cache, as in-process cache like in application servers. So that repeated request we don't need to hit the Redis.
Problem:
One key gets diproprotionate traffic which overloads a single node.
Example:
- Celebrity profile
- Trending post
- Homepage feed
Fixes:
- Key sharding
- Key replication
- Local in-process caching
- Request collapsing
Solutions
1 Key Replication
Store same key on multiple nodes
user:celebrity -> Node A, B, C2 Key Sharding
Split data:
feed:user:1
feed:user:23 Local (In-Process) Cache
Use app memory as fallback:
App memory → Redis → DB4 Request Collapsing
Group identical requests into one
4 Cache Penetration
Attackers (or bad queries) request:
user_id = 999999999 (doesn’t exist)Cache:
- Miss ❌
- DB hit ✅
Repeat this millions of times…
Your DB is under attack.
Problem
Requests for non-existent data bypass cache.
Solutions
- Cache null results
- Use Bloom filters
- Validate inputs early
The Real Lesson
Caching introduces a powerful trade-off:
More caching → faster system
More caching → more inconsistency riskCaching is no just about performance.
It's about control.
You are constantly balancing:
- Speed
- Consistency
- Scalability
And that's why:
Caching is easy to add… but hard to get right.

Leave a comment
Your email address will not be published. Required fields are marked *